疫情之下密切接触者如何精准快速定位
2020新年伊始,人人自危,举国防疫掩盖了新春的热闹。新型冠状病毒肺炎传播迅猛,肆虐全国。
宅在家里,不上班,不聚会,不外出,除了每天关注疫情的发展,作为一个经常出差的人最关心的就是我有没有和确诊病例,同吃,同住,同行。各种查询公布的确诊病例的行走轨迹,关注网上发布的“急寻同乘”等信息。
作为一个混迹大数据检索分析领域十余年的码农,在这个水深火热的时候也按捺不住想对于海量数据下精准快速定位密切接触者这一查询场景给出一点小小心得。
关于上述密切接触者定位,无外乎就是查询出与确诊病例有相同轨迹的人,相同的轨迹可能是他们同乘一辆公交、火车、飞机,也可能是他们同时在一个饭店、会议室、菜摊停留。同一列长长的火车,同一个熙熙攘攘的商场,如何定义路人甲是密切接触者?病例1.5米范围内?同时停留10秒钟以上?本人研究海量数据检索分析、轨迹匹配场景多年,走过很多弯路,也有一些小小心得,在此分享给需要的小伙伴。
一、 密切接触者查什么
密切接触者顾名思义,双方接触的距离、时长、频次。同行同住同车同餐查询有非常多的应用场景,除了在本次疫情中可应用于密切接触者定位外,在很多领域也有非常多的应用场景,这里不讨论业务,不做过多介绍。
二、 密切接触者查询实现的技术难点
密切接触者查询一般依赖于用户的出行位置数据,如通过手机基站定位,或者行车轨迹等,确认出行者的出行轨迹。继而再根据出行轨迹,定位有哪些人的轨迹与上述轨迹重叠,多处重叠即为多次接触。
出行轨迹数据规模庞大,手机基站定位一般被称为手机信令数据,通常手机会每1分钟与周边的基站交互一次(即产生一条数据),对于一个有1亿人口规模的大省来说,每天就会有1亿乘以1440分钟共计1440亿条数据。对于本次疫情,病毒的潜伏周期为14天,则每次查询涉及的数据规模为2万多亿条。
若每条数据1kb大小,则会有2PB的数据产生。假设我们平时用的移动硬盘空间为1TB,则需要2000多个移动硬盘才能存储得下。如何在万亿规模的数据上,快速定位到同行同住同车同餐人员,找到密切接触者,对于计算机系统是一个非常巨大的挑战。
面对这个数据规模,传统的oracle数据库,mysql数据等常规数据库已经无法支撑如此庞大数据量的存放,所以只能依赖于大数据领域的解决方案,故我们从大数据的几个方案剖析,几种实现方案的优劣。
三、 常规实现方法
大数据领域的类hadoop的方案,相信是大多数人员首选思路。类hadoop方案包括:hive、spark,impala,mapreduce等。该类系统采用hadoop 分布式架构,可以承担万亿规模的数据存储,通过数据切片的方式,具备分布式计算的能力。
但此类系统一个明显致命的缺点是,查询数据时采取暴力扫描,2PB数据(2000个1TB的移动硬盘)需要全都读取一遍,且对于密切接触者查询,还涉及多表关联查询,中间需要大量的shuffle,IO的量级可以达到几十PB。
这里先不考虑计算性能,仅仅是这PB级别的暴力扫描,也需要数天的时间,而此时时间就是胜利,早一天排查处理,密切接触者将病毒传播给别人的几率就能减少一个指数级(病毒的传播是非线性的)。故采用暴力扫描的技术方案无法满足疫情当下的需求。
四、 基于大数据之上的索引技术
因暴力扫描存在巨大的IO浪费,故传统数据库采用的索引技术,是否可以考虑应用在大数据领域?我们设想,在常规hadoop方案的技术上,我们给hive或者spark加上一层索引,将会是什么样的概念?
以Spark为例,Spark SQL虽然可以支持各种复杂的查询与计算,但在Spark的底层,数据的获取方式仍旧是一条一条的暴力读取,性能极差。若想提升性能就需要采用堆积机器、大内存、SSD硬盘的方式来提升计算Spark速度。如果我们将Spark底层的数据存储部分改为基于HDFS分布式文件系统之上的索引,即给Spark底层数据加上一层索引,在查询的时候就可以借助索引,避免获取数据时进行一条一条的暴力扫描。该索引技术具有如下优点:
Ø 可以大幅度的加快数据的检索速度;
Ø 可以显著减少查询中分组、统计和排序的时间;
Ø 可以大幅度的提高系统的性能和响应时间,从而节约资源。
早在2009年,我们就开始研究基于HDFS之上的索引技术;在2010年,阿里基于Higo(海狗)系统开发了第一个基于HDFS之上的索引系统,并正式在线上所使用;在2011年阿里以Mdill的名字开源了该技术,通过该技术可以将Lucene索引直接建立在HDFS之上。这个比Lucene官方提供的基于HDFS的索引整整早了3年。
但是索引技术能解决密切接触者的查询问题么?经过这么多年的实战,我很遗憾的给出答案是也不能,纠其根本原因在于随机IO。
通过索引技术,虽然可以快速的定位到相关记录,如迅速搜索找到具体某一个人的轨迹数据,但这些轨迹数据,仍需进一步碰撞出同行人员。我们依然以基站数据为例,我们知道基站数据相对于普通的GPS数据存在精度误差,一些小型的基站在一段时间内,可能有数万个人与之连接,而一些大型的基站,往往会有上百万甚至上千万的连接,而一次查询需涉及数十个甚至数百个基站数据的碰撞(join)。然而目前的索引系统在存储这些记录时是随机的分布在磁盘的不同位置上的。目前的机械硬盘,IOPS在150~160左右,上亿的随机IO几乎不可能完成。故此类索引系统清一色要求必须为SSD固态硬盘,一方面成本极高,另一方面因数据通常采用按块压缩,以及磁盘预读等原因,即便由全固态硬盘支撑,性能也不尽人意。之前做过实战,此类系统,取决于命中的数据条数,对于基站数据查询的性能在几分钟到几小时之间。尤其考验磁盘和CPU的计算能力。
五、 索引结合地理位置检索
基站碰撞,某种意义上是基于地理位置检索的碰撞,我们先了解下常规地理位置检索技术的不足。
目前地理位置检索技术主要为基于GeoHash与Morton码两种方式,两种方式各有优缺点,但究其本质,他们的索引在命中数据后(如某一基站的数据),在磁盘上的分布方式如下图所示,为完全的随机分布。

因上述数据在磁盘上是完全的随机分布,若检索基站对应的数据点非常多,随机IO很高,则会造成整体性能尤为低下。
故我们建议修改数据的存储分布,如某一基站的数据,在磁盘上的存储方式如下图所示。
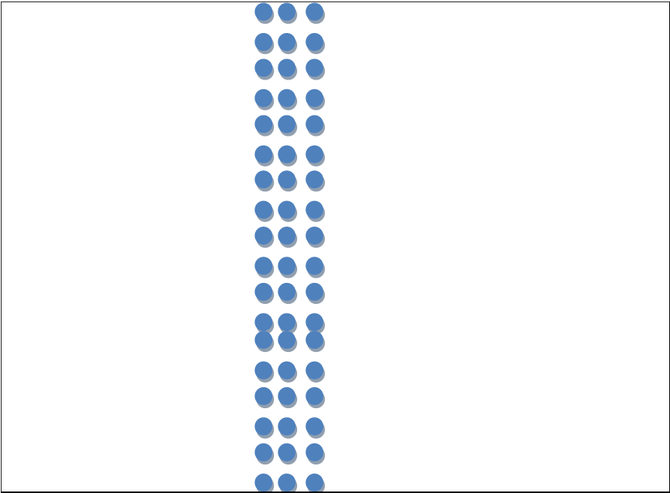
通过这种方式,构造硬盘上的连续读取,可以大幅度的减少随机读取的次数。因常规磁盘连续读取的性能远远高于随机读写的性能,从而大幅度提升查询响应的速度。
但这种方法,只能解决数据的检索性能问题,而密切接触者查询,在检索数据完毕后,还需要根据用户ID与时间进行碰撞,进一步筛选出密切接触者。故仅仅经纬度的数据分布干预也无法完全解决同行人员查询性能问题。为了解决上述问题,我们研究并引入了多列联合索引技术。
六、 多列联合索引技术
1. 多列联合索引技术的背景
长期以来,Lucene在搜索领域的垄断地位多数比不上,基于Lucene之上的Elastic Search与Solr 也是家喻户晓的产品;录信数据库最初的版本也是基于Lucene来实现的,在设计之初经常会遇到跟solr、es同样的问题。如面对几十亿的数据就遇到内存爆掉的问题,此时CPU与IO都飙到系统极限;100亿的数据就需要100多台512G的大内存与SSD盘的硬件支撑,内存参数略微调不好就出现节点掉片,内存OOM的情况。
Lucene在数据碰撞上存在以下设计缺点:Lucene进行分组数据碰撞时需要依赖Lucene的docvalue来加载数据,但docvalue并非有序存储,需将ord文件加载到内存里,做ord映射。这种设计只要数据规模一大,效率就会很差,极易出现爆内存的问题;而且因为是随机读取,磁盘IO飙的非常的高;ES经常遇到的频繁掉片和崩掉的问题都跟docvalue自身的设计有很大的关系。
鉴于上述原因,我们花费了近半年的时间研究多列联合索引技术,旨在为了更好的控制数据的分布,从而让数据能利用上索引技术的前提下,构造出更多的连续(顺序)读取,用以解决随机IO在大数据碰撞分析上性能的不足。
1) 多列联合倒排索引的设计目标
l 加快统计与检索场景的速度。
l 实现多层次关系分析。
l 提升Top N排序速度。
l 加快数据导出的速度。
2) 多列联合倒排索引的实现特点
l 每列之间采用列存储,会根据数据特点自动选择合适的压缩算法。
l 预先干预数据的排序分布,让列存储的压缩更有效。
l 依据查询构造顺序读取。
l 多个列之间存在层次关系。
l 结合分块存储,可以随机访问。
l 使用极少的内存。
l 对象内存重用,减少GC压力。
l 可以压缩的payloads。
3) 应用场景
l 1:统计与检索。
l 2:多层次的关系分析。
l 3:TOP N排序。
4) 因存储连续,适合数据导出。
2. 在密切接触者上的应用方法
针对密切接触的特性,我们可以设计一个具备三个列的多列联合索引。构建构成如下:
1) 索引构建
多列索引={位置},{时间},{身份ID}
{位置}:无需精确到详细的经纬度,只需根据geohash,精确到500米左右的粒度即可,用于构建此500米范围内的连续IO
{时间}:以10分钟为单位处理
2) 查询构建
① 根据常规索引,找到具体某一身份ID的出行轨迹与时间。如
select 经纬度,时间 from table where 身份id=’xxxx’
② 根据轨迹与时间,构造多列联合索引的前两位,如
{位置1},{时间1}
{位置1},{时间2}
{位置2},{时间3}
{位置3},{时间4}
…..
{位置n},{时间n}
③ 根据构造联合索引的前两位,可以初步构造出,哪些记录需要扫描,且因联合索引的的特点,得到的身份ID近似顺序读取,相对于随机读取有近百倍以上的性能提升。
至此,涉及密切接触查询的主要性能问题就已经完全解决了,我们可以根据估计快速的提取到与该病患或疑似人员有密切接触的人员,剩下的就是提取规则,这就是逻辑上的事情了。比如说:我们可以设定,接触时间在6小时以上(家庭成员),或者在几个地区同时都碰撞上(乘坐同一辆公交车)等。
3) 提升计算精度
由于在多列联合索引里的位置和时间,我们采用的是500米与10分钟的粒度,对于部分对精度和时间有严格要求的业务可以采取上节地理位置检索中的方法,通过连续方式的地理位置检索,在不影响性能的前提下,提升计算精度。
疫情当前,借助大数据技术进行防疫控疫,对这场没有硝烟的疫情战争具有重大的意义。截至 2020-02-15 17:44 全国数据统计累计确诊66580例,现存疑似8969例。随着严格高效的排查与隔离措施,疑似病例大幅度减少,更多的疑似病患经确诊后得到了医疗救治,最终确诊人数将会一天一天的下降,相信疫情也会很快得到控制。在此特殊时期,我们呼吁大家要加强防范,减少接触密集人群,避免成为不幸的密切接触者。为了更好的进行技术分享,录信数软公众号近期将进行录信数据库LSQL功能使用相关内容的推送,让大家足不出户即可了解LSQL。遏制疫情,万众一心,我们坚信能打赢这场战“疫”!

